
Attention & Transformer study notes
1 Attention
1.1 attention核心思想
形象化的理解即正如其名,即一次观察只重点关注一个完整信息中的局部特征而相对忽略其他部分。模拟了人脑处理信息过载的方法。

本质上是寻址和求加权平均。相比于卷积来说,这两种方法都是求加权平均,但是attention能够做到根据不同输入动态计算注意力权重,即的输出结果(注意区分模型权重矩阵W),而卷积则是对所有的输入都采取相同的权重。
一般的attention现在是常在encoder-decoder框架下使用,但是也可以脱离该框架单独使用。下图为引入编码解码器框架实现机器翻译的流程图:
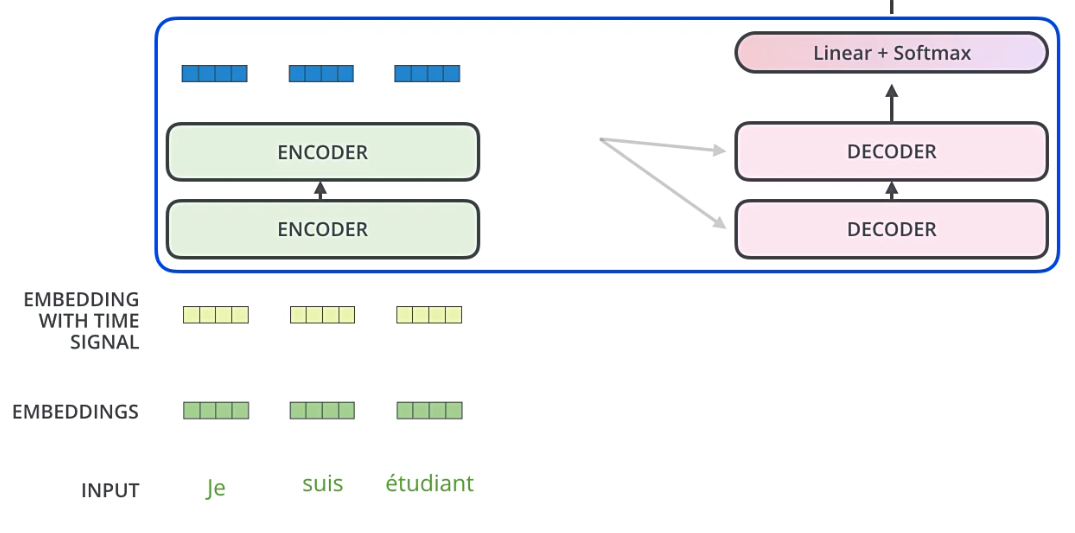
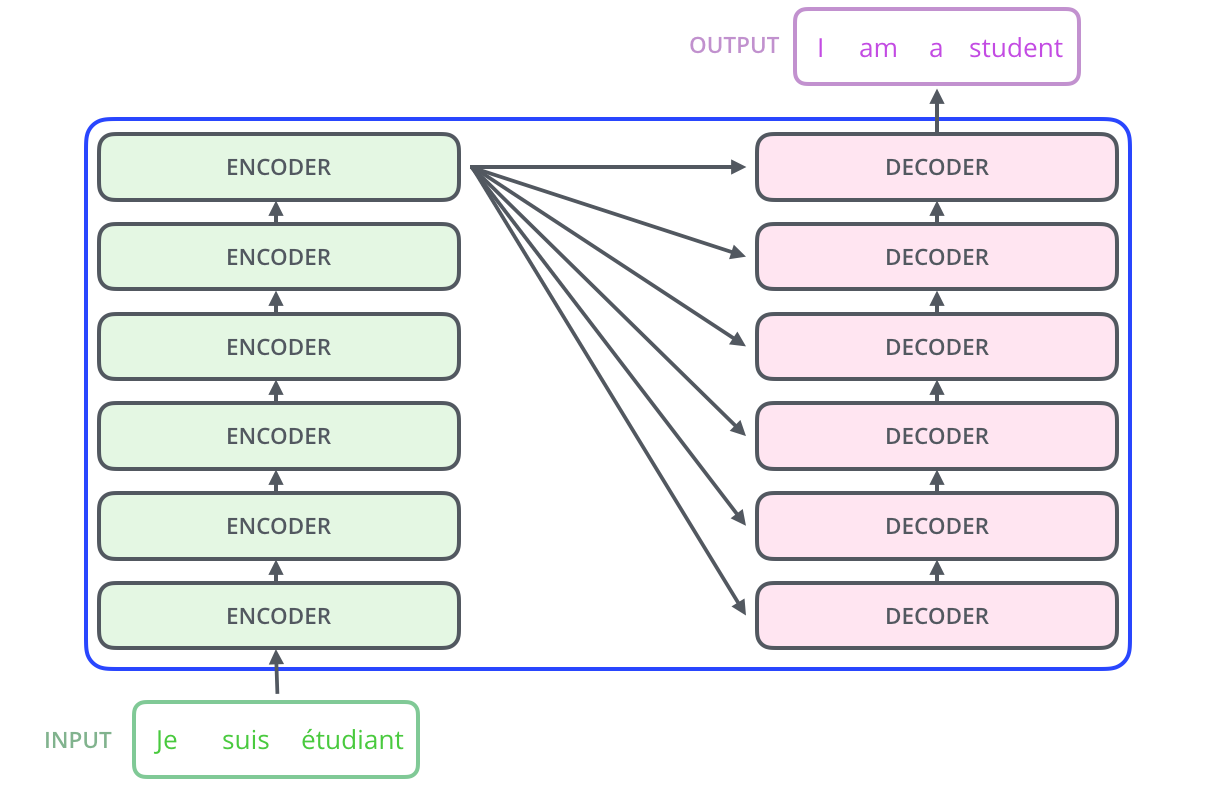
下面是单一attention模块的结构图
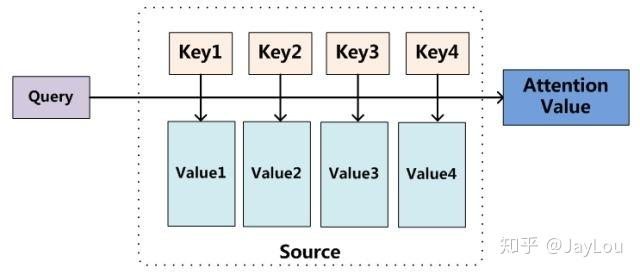
- Query
- 可以把它理解为“我要用什么信息去检索”。
- 例如,在自然语言处理的任务中,每一个位置(单词或子词)的隐藏向量都会映射成一个查询向量,代表“我想从其他位置处获得什么信息”。
- Key
- 可以把它理解为“用来匹配查询的标识”。
- 同样地,每一个位置都会映射成一个键向量,用来让别的位置的“查询”对其进行匹配或“注意”。
- Value
- 可以把它理解为“与键关联的、真正要被提取或聚合的内容”。
- 每一个位置映射得到的值向量,表示在匹配成功后可以提供给查询的“实际信息”。
attention计算的分步分解:
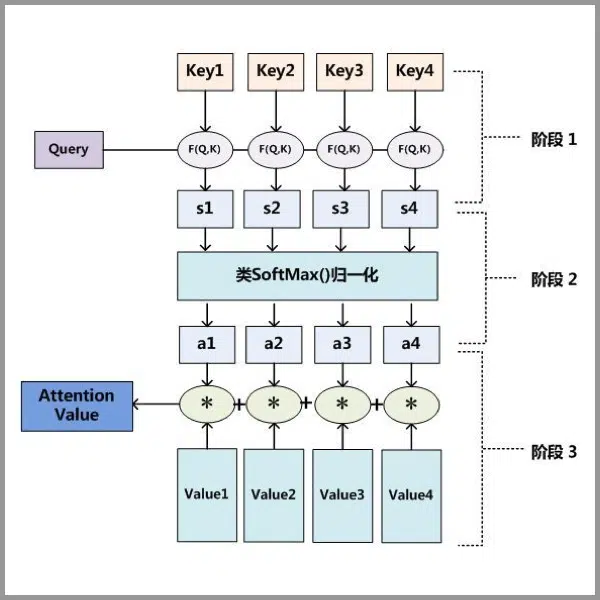
注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。
- 图中F(Q,K)为注意力打分机制,具体打分机制常见如下几种:
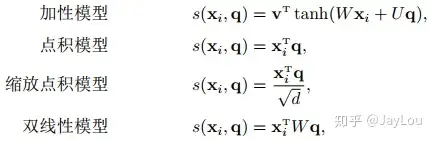
- 以点乘模型为例,通过计算Q和K的矩阵点乘我们可以理解为一个相似度,即为模型对哪个位置最感兴趣的相关性得分,在通过softmax转换为概率分布,即对整个输入的注意力分布
- 计算的得到的权重即为对应位置value的关注度,也就是注意力分数。通过和真实数据value做加权,我们就可以得到经过注意力分数缩放后的向量,来表示重点关注后的信息。
为什么attention机制优于全连接网络和其他深度网络,如CNN和RNN对于长距离序列的特征提取?
全连接网络无法处理变长的输入序列并且每层只处理本地的信息,没有结构链接远处的词汇。
CNN受限于Receptive Field,只能捕捉相邻的信息,因此需要堆叠多层。
RNN对于时间步长依赖强,捕捉远距离依赖时,信息要通过多个中间状态传递,容易梯度消失
最重要的是上述网络的权重都是静态的,不能随着输出长度的变化来动态调整采样权重。在学习文本的时候不可能固定语句长度,理论上不同的输入长度,其连接权重的大小也是不同的。
attention机制能够借助计算注意力权重的机制,根据输入动态调整不同位置的权重。并且能够对输入词的所有token之间的相关性直接通过Query-Key机制计算得到。
1.2 self-attention计算过程
区分self-attention和 attention
普通的attention应用以机器翻译为例,( Q )来自目标语言embedding后矩阵的线性变换,而( K ) 和 ( V )来自原语言。这一套思路是为了找到编码器到解码器的关系,也就是跨序列建模
而self-attention中输入序列本身既是 ( Q ),也是 ( K ) 和 ( V )的信息来源,即Q是对自身输入的线性变换。建模的目标是为了找到序列内部的长距离关系(相比于cnn和lstm),也就是全局建模
这是 Transformer 自注意力的基本单元,公式如下:
[
\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top}{\sqrt{d_k}} \right)V
]
其中 Q、K、V来源为输入矩阵X的线性变换
[
Q = XW^Q, \quad K = XW^K, \quad V = XW^V
]
各个符号含义:
- ( Q \in \mathbb{R}^{n \times d_k} ):Query 矩阵,来自输入通过 ( W^Q ) 映射
- ( K \in \mathbb{R}^{n \times d_k} ):Key 矩阵,来自输入通过 ( W^K ) 映射
- ( V \in \mathbb{R}^{n \times d_v} ):Value 矩阵,来自输入通过 ( W^V ) 映射
- ( W^Q )、( W^Q )和( W^Q )为可训练的权重矩阵
- ( n ):序列长度
- ( d_k ):Key 向量的维度(通常等于 ( d_q ))
- ( \frac{QK^\top}{\sqrt{d_k}} ):QK点乘可以衡量 Query 与 Key 的相关性(相似度),也就是上文提到的注意力打分机制。
- 关于注意力打分机制,《attention is all you need》的作者指出使用dot-product attention与additive attention的效果相近并且原理简单并且能够利用GPU并行计算更加高效。
- 在这里作者在点乘基础上引入了( \frac{1}{\sqrt{d_k}} )作为为缩放因子,用于解决维度过大导致的数值稳定性问题。具体地,当( d_k)维度很大时,Query 和 Key 的点积会变得非常大,因为( QK^\top)是( d_k)个数相乘相加,方差会变大。大数输入到 softmax 会导致:
- 数值不稳定(爆炸)
- softmax 输出变得过于极端,几乎只有一个位置有非零注意力
- 梯度变小(靠近饱和区),训练变慢甚至停滞
- ( \text{softmax} ):将相似度归一化为权重
- 最后用这个权重加权 Value 向量,得到输出
- Multi-head attention
多头注意力的目标是让模型从不同的“视角”理解信息。这也就是实现了对于同一个序列的多次“观察”,并且侧重点(注意力权重)不同。每个头使用不同的投影矩阵对输入进行变换,然后并行计算注意力,最后合并结果。具体计算示意图如下: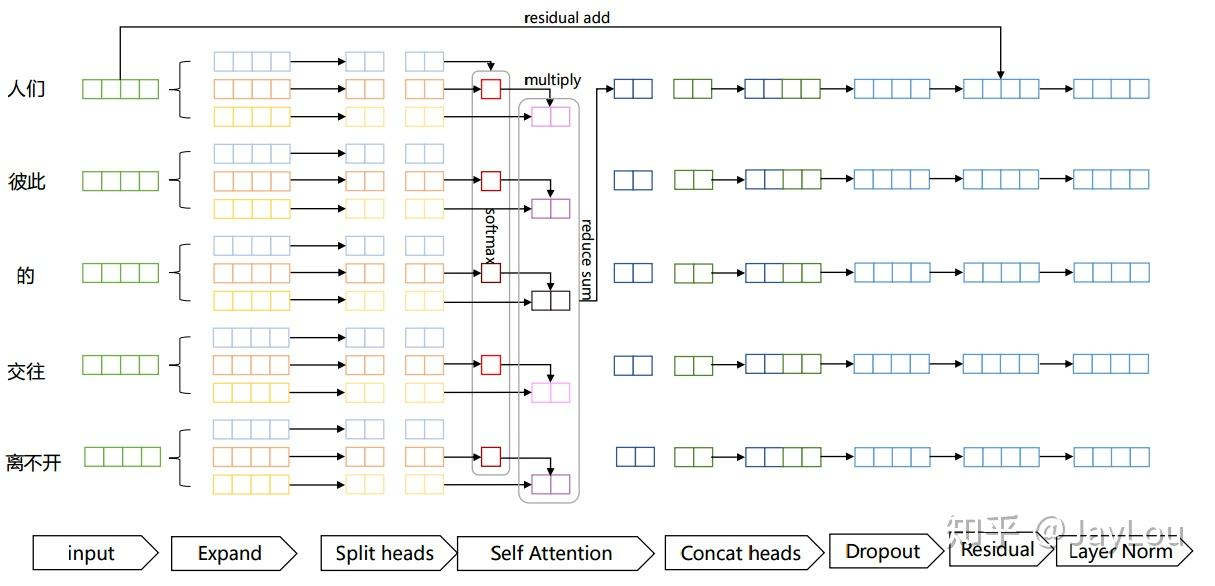
- Expand:实际上是经过线性变换,生成Q、K、V三个向量;
- Split heads: 进行分头操作,在原文中将原来每个位置512维度分成8个head,每个head维度变为64;
- Self Attention:对每个head进行Self Attention,具体过程和第一部分介绍的一致;
- Concat heads:对进行完Self Attention每个head进行拼接;
计算公式如下:
[
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O
]
其中第 (i) 个 head 的计算是:
[
\text{head}_i = \text{Attention}(QW_i^Q, \ KW_i^K, \ VW_i^V)
]
各个参数说明:
- ( h ):head 的数量
- ( W_i^Q \in \mathbb{R}^{d_{model} \times d_k} ):第 (i) 个头的 Query 权重矩阵
- ( W_i^K \in \mathbb{R}^{d_{model} \times d_k} ):Key 权重矩阵
- ( W_i^V \in \mathbb{R}^{d_{model} \times d_v} ):Value 权重矩阵
- ( W^O \in \mathbb{R}^{hd_v \times d_{model}} ):最终的输出投影矩阵
1.3 其他attention机制
硬性注意力 hard attention
- 定义:Hard Attention 是一种选择机制,不是对所有输入做加权平均,而是选择一个或几个位置作为注意力焦点(通常是离散变量),类似“聚焦”。
- 机制:
- 通过概率模型决定“看哪里”(例如使用 Multinomial 分布采样),或者直接选择概率最高的点;
- 只对选中的输入进行处理;
- 最大缺点:选择是离散的,不可导,通常需要使用强化学习(如 REINFORCE)或近似方法(如Gumbel-Softmax)训练。因此为了应用反向传播算法通常transformer中还是使用软注意力机制
2 Transformer
2.1 Transformer网络结构
模型结构如下:
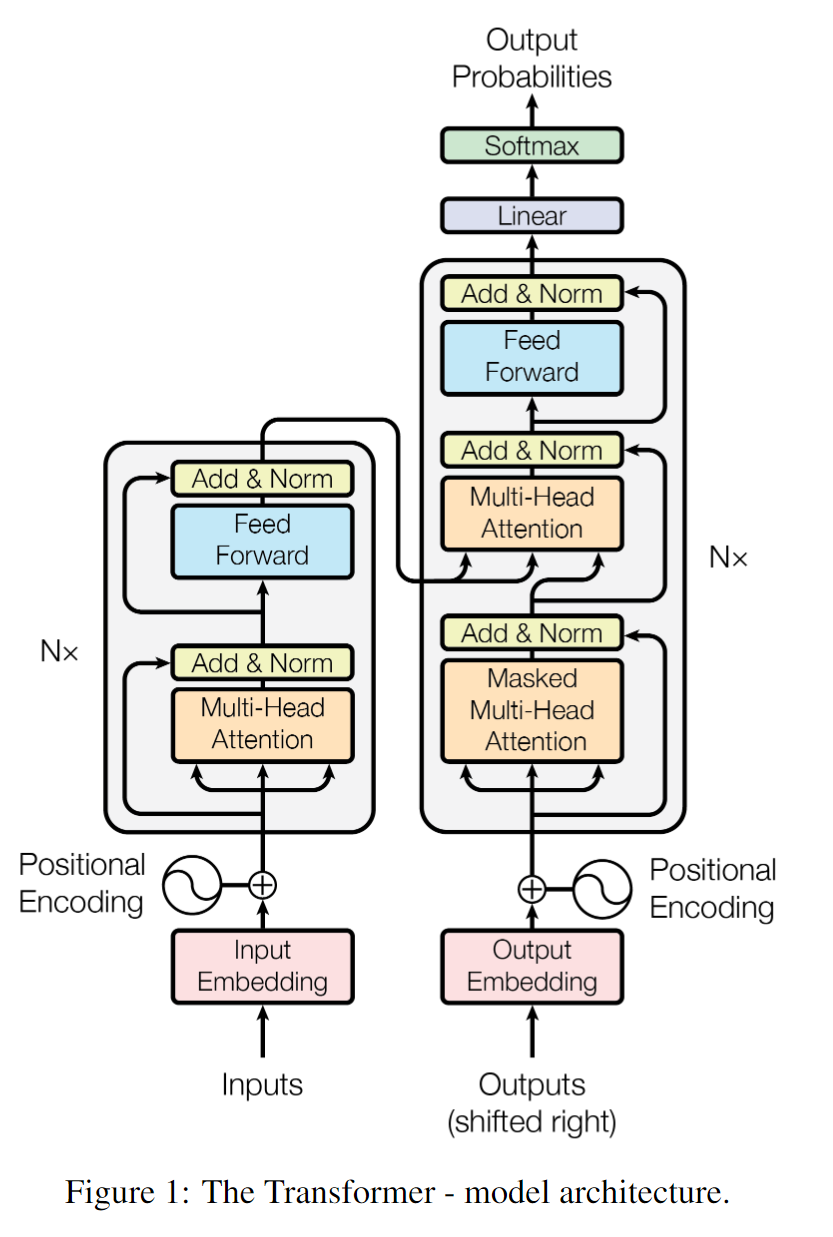
这与seq2seq的结构相同,左边为encoder部分,右边为decoder部分。
单个Transformer模块如下:
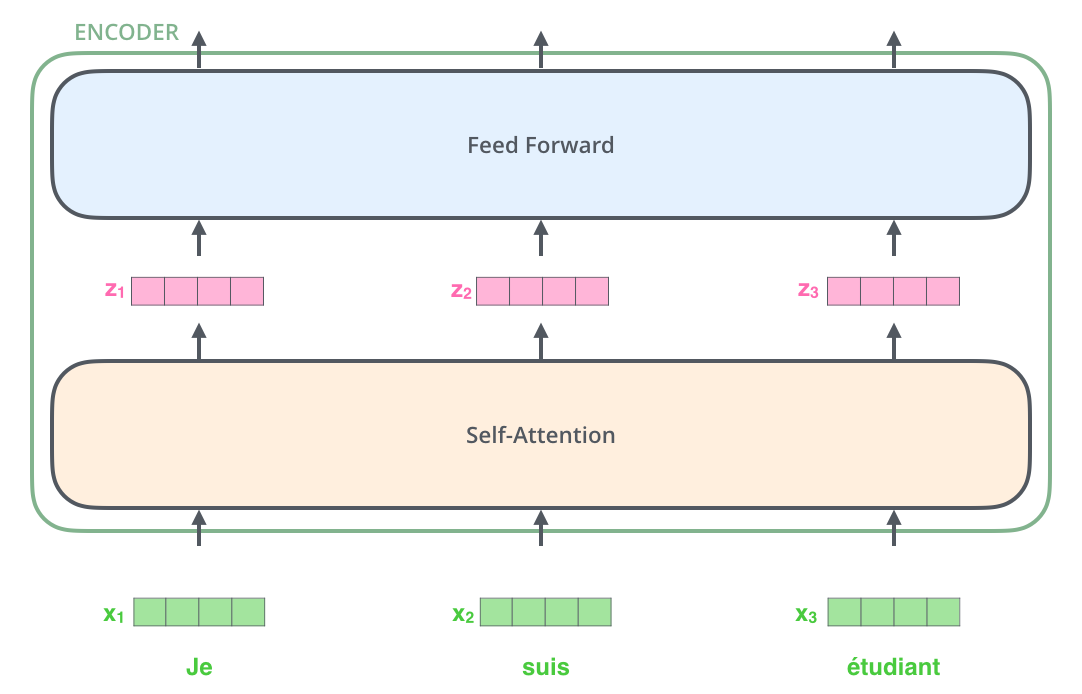
每个Transformer单元相当于一层的RNN层,接收一整个句子所有词作为输入,然后为句子中的每个词都做出一个输出。
- 词嵌入和位置编码:将输入的词 ID 映射成稠密的向量;因为 Transformer 没有循环结构,所以需要显式加入位置信息,在原文中使用了固定的正弦函数,给每个输入的词向量叠加这个固定的向量来表示其位置。
[
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
]
[
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
] - 每个encoder layer包括两个子层
- 多头自注意力(Multi-head self- attention):计算方法同上,并行计算多个self-attention机制,最后再拼接矩阵并作线性变化缩放到原先大小。可以提高算法稳定性,并且同时关注一个序列不同角度的特征
- 前馈网络(feed-forward network):全连接实现线性变换,激活函数ReLU引入非线性
- Residual + LayerNorm(Add & Norm): transformer中每个attention层和FNN后都会加入残差链接来避免深层网络的梯度消失,再做层正则(标准化每个样本在同一层特征维度),即:y = LayerNorm(x + SubLayer(x))
- 在相关改进中有先做LayerNorm再加残差的方法,即y = x + SubLayer(LayerNorm(x))
- 每个decoder layer包括三个子层
- 掩码自注意力(Masked multi-head self-attention mechanism):普通自注意力机制+mask,避免模型提前看到未来预测的序列(大于当前时刻的序列都需要被遮挡)
- Encoder-decoder attention: 同样为multi-head计算,但是Q矩阵来自decoder当前层(self-attention mechanism已经计算出的上一时间i处的编码值),KV矩阵来自encoder的输出,以此来让decoder关注encoder的输出内容
- 输出层最后通过FC层映射到词表,再通过softmax转换为对应词的概率。
2.2 Transformer应用
这里主要提到并对比两种词向量预训练模型,即GPT和BERT。
| 项目 | BERT | GPT |
|---|---|---|
| 使用的 Transformer | Encoder(全注意力) | Decoder(掩蔽注意力) |
| 注意力方向 | 双向(Bidirectional) | 单向(Left-to-right) |
| 训练目标 | MLM + NSP | 自回归语言建模(CLM) |
| 应用任务类型 | 分类、问答、NER、语义匹配等 | 文本生成、续写、对话系统等 |
| 代表模型版本 | BERT-base, BERT-large, RoBERTa 等 | GPT-1/2/3/4、ChatGPT、GPT-neo 等 |
以GPT的pre-train为例:
模型在训练时都会根据不同的训练目标,特殊处理输入的训练数据的结构,以引导模型,让它明白任务类型、理解上下文关系: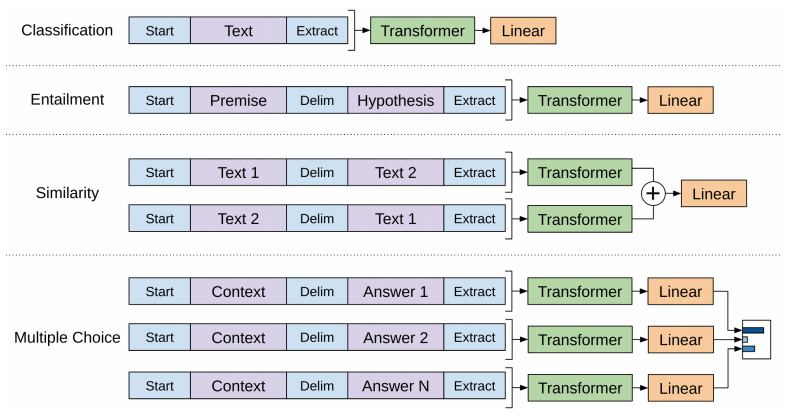
2.2.1 BERT = Transformer Encoder 堆叠的模型
- 每一层都包括:
- 多头自注意力(Self-Attention)
- 前馈网络(FFN)
- 残差连接 + LayerNorm
输入结构:
- [CLS] 句子A [SEP] 句子B
- 每个 token 有:
- 词向量(Token Embedding)
- 位置编码(Position Embedding)
- 分段编码(Segment Embedding)
特点:
- 双向注意力(Bidirectional Attention):
- Attention 可以同时看到左边和右边的词(不同于 RNN 或 GPT)。
- 但不能直接用传统自回归训练方法,因为不能看“未来”——所以用了遮蔽(Masking)。
预训练任务:
- Masked Language Modeling(MLM):
- 随机遮蔽输入中的部分词(如 15%),模型预测被遮掉的词;
- 例如输入:
I have a [MASK] dog.→ 预测[MASK] = black。
- Next Sentence Prediction(NSP):
- 判断句子 B 是否是句子 A 的下一个句子。
BERT (Encoder-only):
[CLS] I like [MASK] dogs [SEP]
└──► Self-Attention: 看到整个句子(含左右)
- 判断句子 B 是否是句子 A 的下一个句子。
2.2.2 GPT = Transformer Decoder 的堆叠结构
- 每一层包括:
- Masked Multi-Head Self-Attention
- FFN
- 残差连接 + LayerNorm
Masked Attention 的作用:
- 每个位置只能看到当前位置及其之前的 token(严格自回归);
- 防止模型在生成时看到未来的信息。
输入结构:
- 不需要 [CLS]/[SEP] 等特殊 token;
- 每次喂入的是前文序列(如 “I have a black”),预测下一个词(“dog”)。
预训练方式:
- Causal Language Modeling(CLM):
- 输入完整句子,模型在每个位置预测下一个词:
- 输入:“The cat sat on the”
- 预测:“mat”
GPT (Decoder-only):
I like big
└──► Masked Attention: 只能看到前面的 I, like, big
→ 预测下一个词是 “dogs”
- 输入完整句子,模型在每个位置预测下一个词: